Optimizing the Retrieval-Augmented Generation Pipeline: A Deep Dive into Embedding Models
Improving the performance of a Retrieval-Augmented Generation (RAG) pipeline might seem like a daunting task, especially when there are multiple components to consider. However, if you focus on one critical piece—the embedding model—you can make significant enhancements without overhauling your entire system. In this article, we’ll walk you through our journey of fine-tuning our RAG pipeline, sharing insights and practical solutions that can help you achieve faster, more relevant search results for your copilot application.
Introduction: Focusing on What Matters
When it comes to enhancing our RAG pipeline, the retrieval part quickly emerged as the natural point for improvement. Instead of a complete rebuild that would risk introducing new complexity and higher costs, we set out to optimize our existing embedding model. This approach allows you to boost performance by tweaking a single component rather than the whole architecture.
With our focus narrowed to the embedding model, we aimed to improve how our system understands and retrieves data seamlessly, which, in turn, can lead to better user experiences when interacting with our copilot powered by Elasticsearch.
The Goal: Enhancing Search Results with Hybrid Technology
In our current system, Elasticsearch forms the backbone of our copilot’s search capabilities. Documents in our database are split into manageable sections through an intelligent sectioning algorithm. This allows the system to efficiently retrieve the most relevant sections when a user submits a query.
Here’s how it works:
- When a query is made, roughly 50 of the most relevant sections are fetched for further evaluation.
- The full documents from which these sections are taken are then retrieved to provide context for the language model (LLM) to process.
Our method uses a hybrid search approach that mixes traditional keyword-based methods with vector-based search. By adjusting a “boost” parameter, we can decide which method should weigh more heavily during the search. For instance, we standardized on a boost value of 100 for our tests to offer a clear comparison among various embedding models.
Preparing Test Data: Building a Robust Test Suite
Before diving into the different embedding options, it’s crucial to have a solid set of test data. We assembled a synthetic dataset comprised of around 10 diverse documents. These documents covered multiple domains, such as finance, travel, and company policies, ensuring our tests catered to real-world scenarios.
Each document is broken down into segments, allowing us to generate multiple test cases. For instance, consider a simple set of lines:
“We have a cat in home.
Our home is in Miami.
We like living in the USA.”
In this example, each line becomes its own section, which makes it possible to evaluate whether our system correctly identifies and ranks the most relevant sections in response to a query like “What animal do you have in your home?” or “Where do you live?”
To streamline our testing process further, we used a tool called promptfoo. This handy tool not only makes it easier to visualize the search results but also helps us design test queries across multiple programming languages like JavaScript and Python.
Creating Diverse Test Queries: A Closer Look
For every document, we created between 10 and 15 test queries. These queries were crafted to challenge the models’ semantic understanding and ability to adapt to different content types—be it plain text or tables. The goal was not only to see whether the right document section was returned but also to understand how deeply the model grasped the meaning behind each query.
Imagine you’re hosting a small experiment where you want the first sentence about a cat to appear at the top when someone asks, “What pet do you have?” Similarly, if your document says, “Our home is in Miami,” a search for “Where is your home located?” should naturally push that segment to the forefront.
Testing Methodology: Using promptfoo for Clear Insights
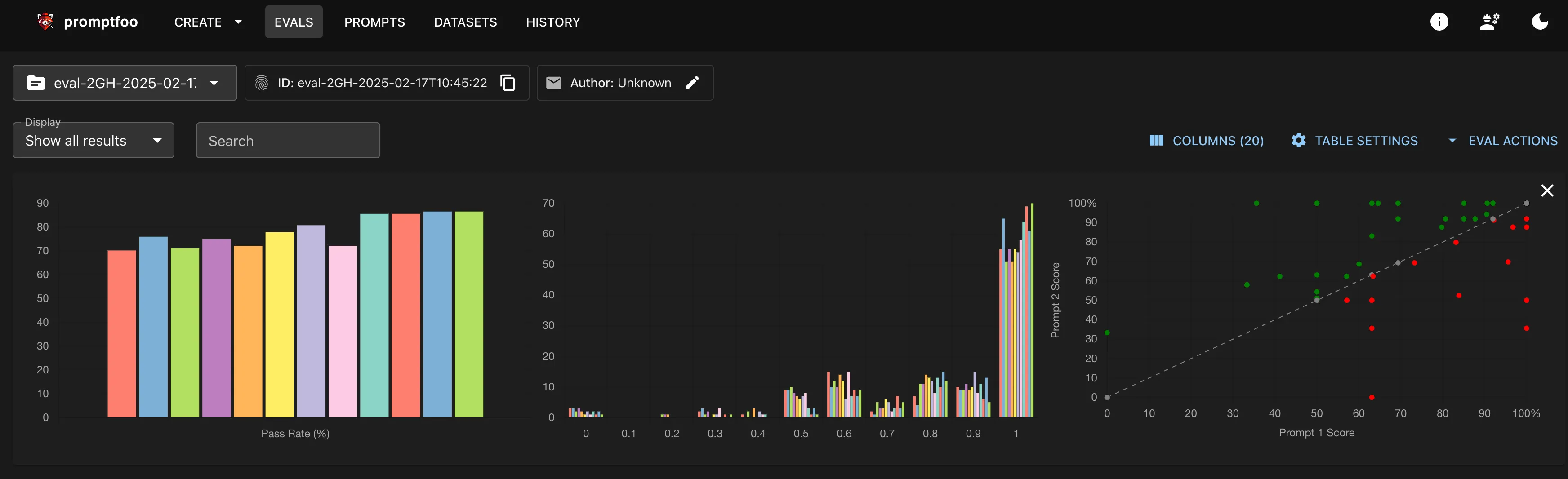
Our testing methodology leverages promptfoo, a versatile testing framework known for its ease of use and impressive visualization features. With promptfoo, we designed a suite composed of 119 specially crafted queries covering a broad spectrum of topics. This comprehensive approach meant that every query not only tested the semantic depth of our models but also examined their response consistency across various languages such as English, Italian, Polish, French, Portuguese, UK English, Spanish, and German.
Even better, switching between different embedding models showed minimal effects on search latency. This indicates that while you’re refining the accuracy of your search results, the overall speed of your system remains reliable and consistent—a win-win situation for both developers and end users.
Analyzing the Results: Comparing Embedding Models
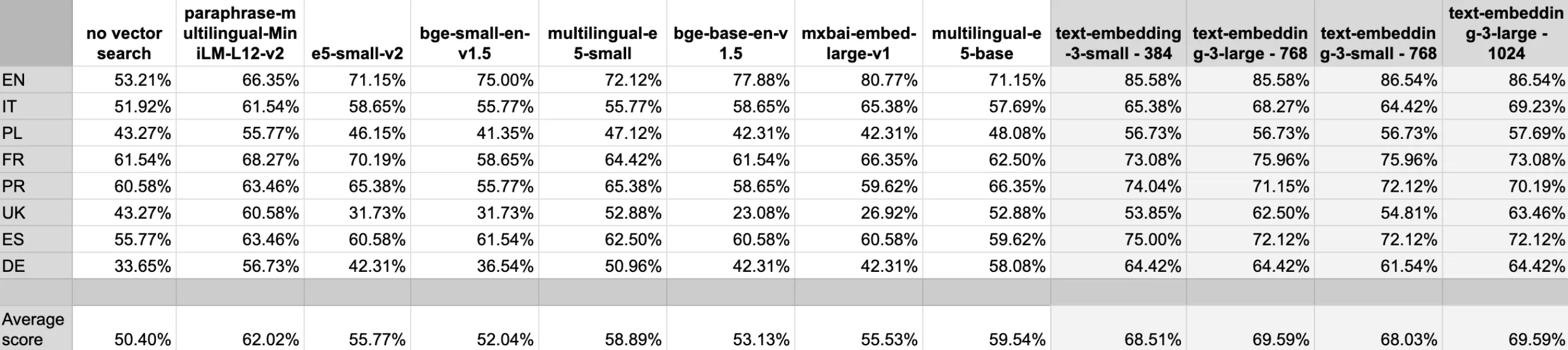
We evaluated several embedding models to gauge which one delivered the best performance without compromising on speed or resource usage. Here’s a glimpse of our experiments:
- Our current model (paraphrase-multilingual-MiniLM-L12-v2) served as the baseline.
- We also tested specialized models like e5-small-v2 and bge-small-en-v1.5, among others.
- OpenAI’s text-embedding-3 models came in various dimensions (384, 768, and 1024) to see how embedding size affects search quality.
The results were eye-opening. For instance, OpenAI’s embeddings generally delivered higher passing rates according to the NDCG@K metric, which measures how many correct sections appear in the top positions of the search results. Multilingual models, in several cases, performed better than those designed only for English, emphasizing the importance of tailoring your search engine strategy to diverse user bases.
Conclusion and Next Steps: Mapping Out the Future
While our testing highlighted clear performance differences among the embedding models, the decision isn’t as simple as choosing the one with the highest score. It’s more about considering the context in which the model will operate. When selecting a model, think about:
- The specific requirements of your use case.
- How the model integrates with your current search engine technology.
- The nature and diversity of your document formats.
For us, the next phase involves deploying the best-performing model into our production environment. But deploying is just the start. We will also be implementing robust monitoring of customer satisfaction metrics, allowing us to gather real-world performance data. This will help ensure that the theoretical improvements from our tests translate into tangible benefits for users.
Optimizing a RAG pipeline is much like tuning a musical instrument: small, precise adjustments can lead to a harmonious system that strikes the perfect chord with its users. With our focus on the embedding model, we’ve discovered a practical path to enhancing search relevance without excessive resource allocation. As technology continues to evolve, so will our strategies—always aiming for a system that’s fast, accurate, and user-friendly.
By sharing our journey, we hope to offer you the insight and inspiration needed to refine your own RAG pipeline. After all, a well-optimized search system is not just about cutting-edge technology but also about delivering a seamless experience that meets the real-world needs of your audience.